





Accelerated Methods in {Multi-Modal, Multi-Metric, Many-Model} CogNeuroAI
A GPU-accelerated tutorial on probing the representational alignment of brains, minds, and machines across many models and metrics.
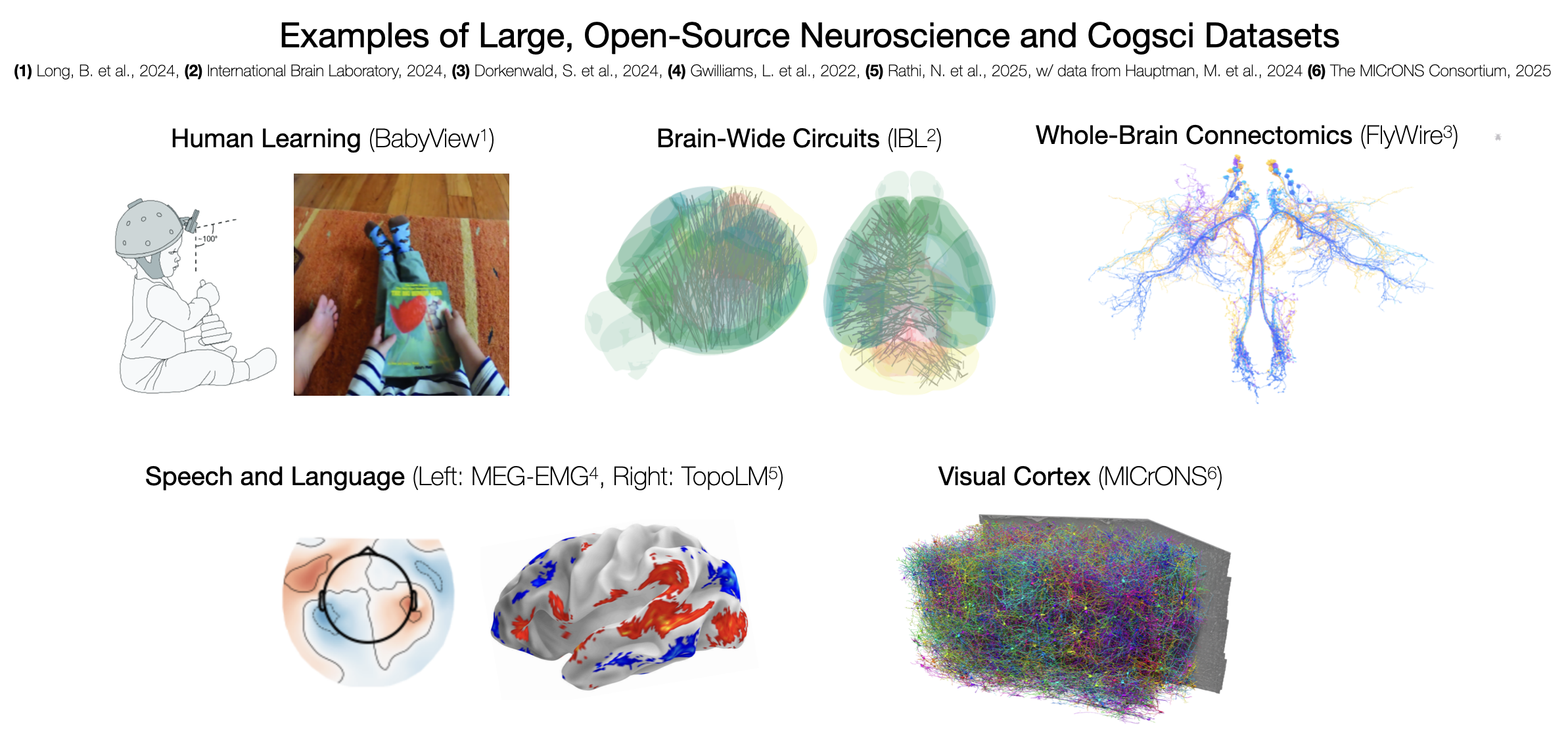
We believe a workshop focused on ML applied to such datasets is timely and presents a clear opportunity to help forge collaborations. Thus, we designed the workshop to be highly interactive. In addition, we invited speakers who have led large, open-sourced data initiatives or analyzed key datasets like those mentioned above.A key differentiator of our workshop is its focus on the rich diversity and heterogeneity of emerging neuroscience and cognitive science datasets. These are not your standard ML benchmarks; they span a wide array of data types including time series, images, videos, text, and even unconventional structures like connectome graphs from MICrONS. Each dataset possesses highly idiosyncratic meta-information, such as the spatial coordinates of electrodes in MEG recordings, that invites the development of tailored, sophisticated AI solutions. This departure from generic datasets encourages a move beyond one-size-fits-all foundation models, precisely the kinds of directions we aim to explore.
| Time | Event | Details/Speakers |
|---|---|---|
| 7:30 - 8:00am |
Poster Setup |
Time for presenters to set up their posters. |
| 8:00 - 8:10am |
Opening Remarks |
|
| 8:10 - 8:40am |
Invited Talk 1 |
Dan Yamins (Stanford) |
| 8:40 - 9:10am |
Invited Talk 2 |
Cengiz Pehlevan (Harvard) |
| 9:10 - 9:25am |
Coffee break |
Coffee break |
| 9:25 - 9:55am |
Invited Talk 3 |
Laura Gwilliams (Stanford) |
| 9:55 - 10:40am |
Contributed Talks 1 |
Lightning talks from featured contributions
|
| 10:40 - 11:30am |
Poster Session 1 |
Interactive session with contributed works and discussion on datasets. |
| 11:30am - 1:15pm |
Lunch / Mentorship Lunch |
Presenting authors of contributed works and invited speakers will participate in a mentorship lunch. |
| 1:30 - 2:00pm |
Invited Talk 4 |
Ila Fiete (MIT) |
| 2:00 - 2:30pm |
Invited Talk 5 |
Rajesh Rao (University of Washington) |
| 2:30 - 3:00pm |
Contributed Talks 2 |
Lightning talks from featured contributions
|
| 3:00 - 3:30pm |
Invited Talk 6 |
Bria Long (UCSD) |
| 3:30 - 3:35pm |
Coffee Break |
Coffee break |
| 3:35 - 4:10pm |
Panel with invited speakers |
|
| 4:10 - 4:15pm |
Closing Remarks |
|
| 4:15 - 5:00pm |
Poster Session 2 |
Interactive session with contributed works and discussion on datasets. |
View all accepted Findings on OpenReview.
For more details of the tutorial track, please visit our tutorial website.
A GPU-accelerated tutorial on probing the representational alignment of brains, minds, and machines across many models and metrics.
Hands-on overview of the Visual Behavior Neuropixels dataset and tools for large-scale neural data analysis.
A framework for building open human fMRI foundation models via improved preprocessing, dataset aggregation, and in-context representation learning.
End-to-end walkthrough for neural keyword spotting on the LibriBrain MEG corpus, from task setup to evaluation under extreme class imbalance.
A pipeline for discovering and interpreting latent structure in neural population activity.
A large-scale EEG + eye-tracking dataset of natural reading with annotations of mind-wandering, enabling research on attention, language, and ML.
We invite submissions in the following two tracks. The review process is double-blind through our OpenReview portal for each track, and the submissions should be anonymized. Both tracks are considered non-archival will not conflict with future publication.
Reciprocal Review: To help ensure a fair and high-quality review process, we ask that each submission nominate at least one author to be available as a reviewer for the DBM workshop during September 9-19. It is sufficient if the nominated author has already signed up as a reviewer for the workshop.
Submissions should present original research on computational methods, theoretical frameworks, or quantitative findings that are applicable to neuroscience or cognitive science. We welcome 4-page or 8-page submissions of unpublished work (including work currently under review elsewhere). Previously published work is not eligible.
Examples:Submission Template
Please use our official submission template when preparing your paper for the Findings track.
Submissions not using the template may be desk-rejected. For authors new to LaTeX, we recommend
using Overleaf. If you have any questions, please
reach out to us.
Submissions should present pedagogical notebooks or blog posts discussing ML methods, neuroscience / cognitive science datasets, or conceptual frameworks, with the goal of facilitating interdisciplinary collaboration.
Examples:Requirements
Submissions to the tutorials track will be evaluated on pedagogical quality and relevance to the themes of the workshop. Tutorials do not need to be original research—it is fine to present existing datasets or methods (with appropriate attribution) in a more accessible way. Any dependencies (code, data, etc.) should be included in the submission with clear instructions for use.
Additional instructions for submitting tutorials are provided here.










