CONFORM: A Project to Create Crowd-Sourced Open Neuroscience fMRI Foundation Models
We propose CONFORM (Crowd-Sourced Open Neuroscience fMRI Foundation Model), a project that will bring together recent advances in neural data processing and analysis with a novel, crowd-sourced infrastructure. This transformative approach will overcome several current challenges in creating a foundational human fMRI model for vision: collecting massive amounts of data from a handful of participants is neither scalable nor sustainable; the number of participants is small for such datasets; stimulus diversity is limited; and generalizability to different populations is poor. CONFORM will overcome these limitations by combining a powerful denoising method (PSN), a scalable framework for aggregating existing fMRI datasets (MOSAIC), and a meta-learning model that enables generalization with much smaller data from new participants (BraInCoRL). Our collaborative effort will produce models built on unprecedented scale and diversity—ultimately with hundreds of participants and hundreds of thousands of naturalistic image and movie stimuli—and provide the tools for continuous expansion of the underlying dataset. This ``crowd-sourced'' approach will allow many more researchers to leverage state-of-the-art NeuroAI methods using the scale of data they typically collect, democratizing access to powerful models and accelerating scientific discovery for a wide range of neuroscientific domains and populations.
Background and Introduction
Creating a foundational human fMRI model is a critical next step for extending modern NeuroAI
Historically, a significant impediment has been that most fMRI studies have small sample sizes and a low number of observations per session; the latter also leading to poor stimulus diversity. As a result, typical fMRI experiments sample only a tiny fraction of the human population and the vast space of real-world visual, auditory, or linguistic inputs. These limitations impeded efforts to draw robust conclusions from fMRI data and to integrate insights from modern AI systems into our understanding of the human brain—a challenge that is exacerbated by the inherently noisy BOLD signal.
In visual neuroscience, a first step in meeting this challenge has already been taken through the collection of large-scale fMRI datasets, which typically include brain responses from a small number of participants each scanned over many repeated sessions (15-40 hours-long sessions), who view a large number of stimuli (5000-10,000 stimuli per participant)
-
Participant burden and attrition: Successful data collection at this scale depends on heroic efforts by both experimenters and participants. The time commitment and scheduling complexities are onerous: participants, experimenters, and scanners must remain consistently healthy and available (e.g., in both the BOLD5000 and NSD datasets at least one participant failed to complete the study
; in the THINGS dataset one participant was canceled due to “technical issues” ). -
Limited sample size: Even with this extraordinary amount of effort, data was collected from only 3-8 participants—a small number that does not support the hoped-for population diversity expected of human neural foundation models.
-
Constrained stimulus diversity: Stimulus diversity is necessarily limited by small participant pools and the need for stimulus repeats and/or overlap across participants
. Even within a single recurring participant, only a limited number of observations are possible. Moreover, controlled tasks and stimulus selection methods have further reduced diversity in the visual images included in each dataset: NSD uses only COCO images (only 80 object categories , which leave gaps in many regions of natural image space ), BOLD5000 uses COCO as well as SUN and ImageNet images, and THINGS uses a larger number of “concepts”, but depicted as single cropped objects that show little context . -
Infrastructure challenges: Creating the infrastructure for data management and distribution is a considerable technical challenge. Short-term it requires a robust and replicable data processing pipeline and a reliable platform for data distribution. Long-term it requires stability—years later the distribution website should remain readily accessible.
-
Financial barriers: The monetary costs of collecting data can present a challenge to any single lab (e.g., five participants across 25 × one hour scans could easily cost on the order of $100,000) and risks over-representing the interests of the small number of labs with the necessary resources.
Despite their increased scale relative to standard fMRI studies, these datasets still present significant challenges in the construction of NeuroAI models. The number of observations and participants is still small for purposes of model training, and data quality is dependent on preprocessing methods. More importantly, prediction accuracy and decoding performance are typically high only when trained and tested within the same participant—due to inherent structural and functional differences between individual brains and, at present, weak methods for generalizing across them. Consequently, when models are applied across participants, even within the same study, their performance and decoding capabilities decrease dramatically.
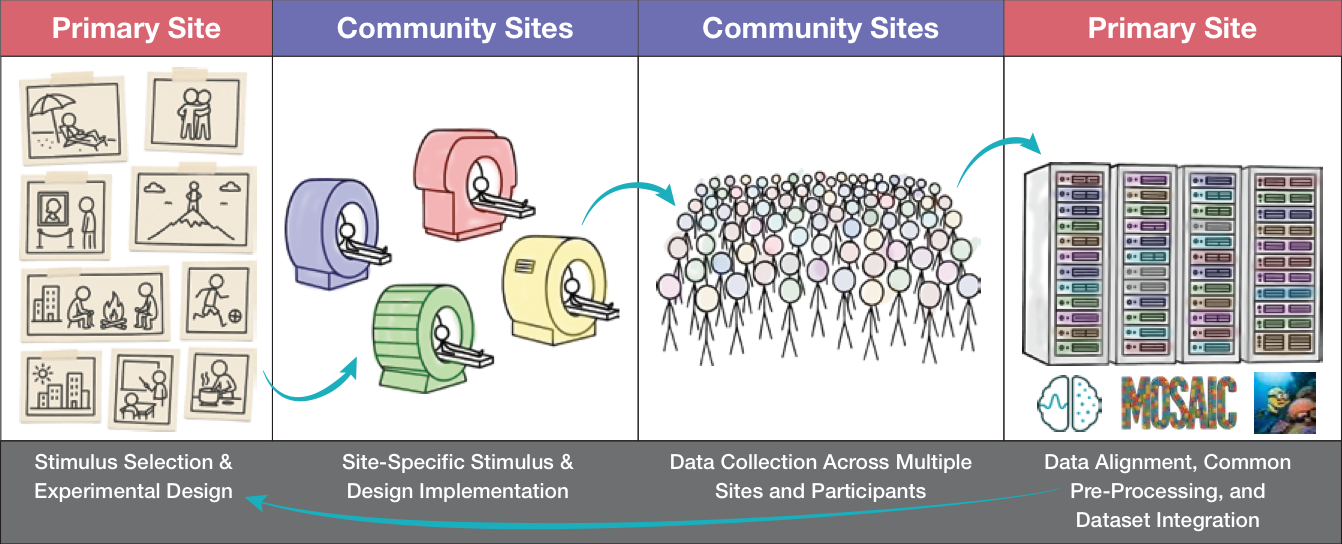
Figure 1: CONFORM workflow. A single, optimized experimental design is distributed to multiple sites for data collection. The collected data is then centralized for preprocessing, alignment, and integration into a foundational dataset. This process creates a continuous feedback loop, allowing the dataset to grow in size and diversity, which informs future experimental design and provides the basis for a strong foundation model.
Towards a Dynamic Foundation Model for Visual fMRI
We propose CONFORM (Crowd-Sourced Open Neuroscience fMRI Foundation Model)—a strategy for building foundational human visual fMRI models through community-contributed datasets and models. Following previous efforts in systems neuroscience
-
A larger-scale and highly diverse dataset that aggregates close to 100 participants and 100,000s of natural scenes depicting 1000’s of object categories/concepts in context. “MOSAIC”
is a scalable framework for combining extant fMRI datasets , using common preprocessing and registration, into a single, extremely large-scale and extensible vision dataset. MOSAIC Repository: https://registry.opendata.aws/mosaic/ -
Higher data quality through an enhanced preprocessing pipeline to improve the signal-to-noise ratio of measured BOLD responses. Building on GLMSingle
and Generative Modeling of Signal and Noise (GSN ), we are developing PSN (Partitioning of Signal and Noise)—a powerful low-rank denoising method that optimally separates signal from noise in neural data, outperforming trial-averaging and PCA, especially when noise is structured or complex (as in fMRI). PSN Repository: https://github.com/jacob-prince/PSN -
Enhanced generalization to new participants from outside-of-dataset studies using “BraInCoRL”—a meta-learned in-context foundation model that enables generalization using only a small amount of additional data
. BrainCoRL Repository: https://github.com/leomqyu/BraInCoRL -
Crowd-sourcing infrastructure to support the continuous integration of data from new studies across unique participants and data collection sites.
Building on these methodological advances and the lessons learned from distributed large-scale fMRI datasets
We are taking on this challenge by integrating and further developing recent advances in fMRI preprocessing, data aggregation, and generalization. CONFORM will also include the infrastructure for continuously expanding the dataset’s size and the diversity of its stimuli
The locally directed model is straightforward: the CONFORM distribution website will also accept contributions. In contrast to other neural data repositories
The globally directed model is more ambitious and forward-looking, and offers a greater potential payoff. We will provide a complete, turn-key study design to participating research sites, streamlining the data collection process. We will optimize the selection of stimulus images to achieve the best possible distribution of images within natural image space across many participants
CONFORM’s framework towards a scalable foundation fMRI model will enable powerful insights into human vision. Datasets within CONFORM will continue to grow in size and stimulus diversity as the community contributes data. Critically, the resultant models will achieve improved generalization to new participants across diverse subpopulations, requiring only a relatively small amount of data per individual. As such, CONFORM will dramatically broaden the accessibility of NeuroAI methods, empowering researchers in a much wider range of scientific domains to make new discoveries.
Improving Data Quality—PSN
The recently introduced GLMSingle preprocessing pipeline dramatically improves the signal-to-noise ratio of measured BOLD responses acquired using standard fMRI methods
PSN addresses a core challenge in building a truly foundational fMRI dataset by maximizing the amount of stimulus-driven information (signal) that can be recovered from each participant’s measurements, while partitioning out the influence of other sources of variability (noise). Conventional denoising strategies such as trial averaging are straightforward and widely used, but they rely on the assumptions that noise is independent across trials and uncorrelated between voxels. In actuality, these assumptions are often violated in fMRI data, where noise can be structured, spatially correlated, and non-stationary. Similarly, PCA-based low-rank denoising identifies directions of highest variance but does not explicitly distinguish between signal and noise, leading to bias when noise variance is large or when signal and noise share overlapping subspaces
PSN addresses these limitations by extending the GSN framework
Critically, PSN relies on cross-validation to determine the optimal number of signal dimensions to retain, with thresholds chosen either at the multi-voxel or single-voxel level, depending on the data’s heterogeneity in feature tuning and signal-to-noise ratio. This cross-validated tailoring of denoising parameters will be particularly important given CONFORM’s aim of integrating large, multi-site datasets, where measurement quality can vary widely across participants, scanners, and brain regions.
In simulations with known ground truth, PSN consistently recovers more accurate signal estimates than trial averaging or PCA-based methods, achieving lower variance without introducing substantial bias. Applied to real datasets, including primate electrophysiology and human fMRI, PSN yields substantial gains in cross-validated encoding model performance and improves the interpretability of model-derived feature visualization (manuscript in preparation). In the context of CONFORM, applying PSN to every contributed dataset ensures that all data entering the foundation model are maximally informative, optimized for data quality and reliability, and robust to the structured noise sources inherent in large-scale, crowd-sourced fMRI. Finally, because non-stimulus-driven sources of neural variability may themselves be of scientific interest, PSN also enables these components to be cleanly separated for downstream analyses that focus on modeling noise rather than signal.
Integration of fMRI Data Across Studies—MOSAIC
Individual fMRI experiments face practical constraints that create trade-offs between the number of participants, the number of experimental trials, and stimulus diversity. Any resulting conclusions are thus limited in scope. However, the aggregation of existing fMRI datasets, here called MOSAIC (Meta-Organized Stimuli And fMRI Imaging data for Computational modeling), achieves a vastly larger scale useful for measuring cross-dataset and cross-subject generalization and training of high-parameter artificial neural networks.
MOSAIC
At present, MOSAIC contains 430,007 fMRI-stimulus pairs from 93 participants across 162,839 unique image stimuli. The stimuli are further divided into 144,360 training stimuli, 18,145 test stimuli, and 334 synthetic stimuli for rigorous model training and evaluation. Their shared preprocessing pipeline uses open source frameworks and is thus compatible with methods advancements such as PSN and expansion to other registration spaces such as subject native. Crucial to CONFORM, datasets can be added to MOSAIC post-hoc regardless of experimental design, acquisition, and size.
MOSAIC is a critical first step to enable researchers to overcome individual dataset limitations and tackle complex research questions at an unprecedented scale. The MOSAIC dataset and preprocessing code will be available soon for download. In tandem with the MOSAIC team, the larger CONFORM community will work to leverage MOSAIC’s extensible design to allow the seamless integration of new datasets, creating an evolving foundation for collaborative human vision research.
Generalizing Across Participants and Studies in a Low Data Regime—BraInCoRL
Different datasets may utilize different stimuli, employ different scanning parameters, and collect data from diverse populations. This makes it challenging to build generalizable models that predict neural activity across diverse participants. Traditional approaches require large, participant-specific fMRI datasets, limiting their scalability for clinical and research applications. This variability in cortical organization—driven by anatomical and functional differences, developmental experiences, and learning—necessitates a framework that can adapt to new individuals with minimal data while capturing shared functional principles of visual processing.
To address this, BrainCoRL (Brain In-Context Representation Learning)
BrainCoRL outperforms traditional voxelwise encoding models in low-data regimes, generalizes to entirely new fMRI datasets acquired with different scanners and protocols, and provides interpretable insights into cortical selectivity through its attention mechanisms. Notably, the framework can also link neural responses to natural language descriptions, opening new possibilities for query-driven functional mapping of the visual cortex. By dramatically reducing the data requirements for accurate neural encoding models, this work paves the way for more scalable and personalized applications in both basic neuroscience and clinical settings, where understanding individual differences in brain organization is crucial for diagnosis and treatment.
Impact and Conclusions
Although existing large-scale fMRI datasets have been valuable, used in hundreds of studies to support a wide range of novel scientific discoveries, they are limited by their single-site, small-N approach. To move beyond this, we propose CONFORM—a unique crowd-sourcing strategy that leverages recent advances in data processing, data aggregation, analysis, and a new crowd-sourced infrastructure. This new approach directly addresses the financial and logistical challenges of collecting large datasets while enabling unprecedented stimulus diversity. However, simply crowd-sourcing data is not enough; CONFORM’s success will be predicated on the specific data and modeling optimizations we introduce to handle the multifaceted noise inherent in fMRI. Moreover, by creating models that can effectively predict new data with only a small amount of information, we will dramatically broaden the accessibility of NeuroAI methods. This will empower a much wider range of researchers to leverage the power of modern AI using the typical scale of data they collect, ultimately accelerating scientific discovery.
Critically, generalizing across individuals requires addressing both biological differences and technical noise sources, such as artifacts from different scanners and motion. We directly tackle these challenges through a three-pronged approach:
-
Data Acquisition: Collect a limited amount of data from each participant, including repeated and partially overlapping stimuli across the population, to boost both data quality and stimulus diversity.
-
Denoising: Apply a two-level denoising strategy. Use GLMsingle to optimize the signal-to-noise ratio within each subject and, then, apply PSN to separate stimulus-related variance from idiosyncratic noise, improving data quality and interpretability.
-
Alignment: Learn a mapping from the denoised data into a shared representational space, thereby allowing us to make accurate predictions across individuals. This can be achieved through advanced methods such as BrainCoRL, which does not require overlapping stimuli, or using standard functional alignment techniques that rely on overlapping stimuli in the denoised data.
By integrating and advancing these tools to create a true foundational model, we can answer downstream questions using the dataset population to make predictions about new individuals or clinical populations. For example, recent advances in visualizing and labeling neural representations of object categories